# Ch2 知识表达与推理
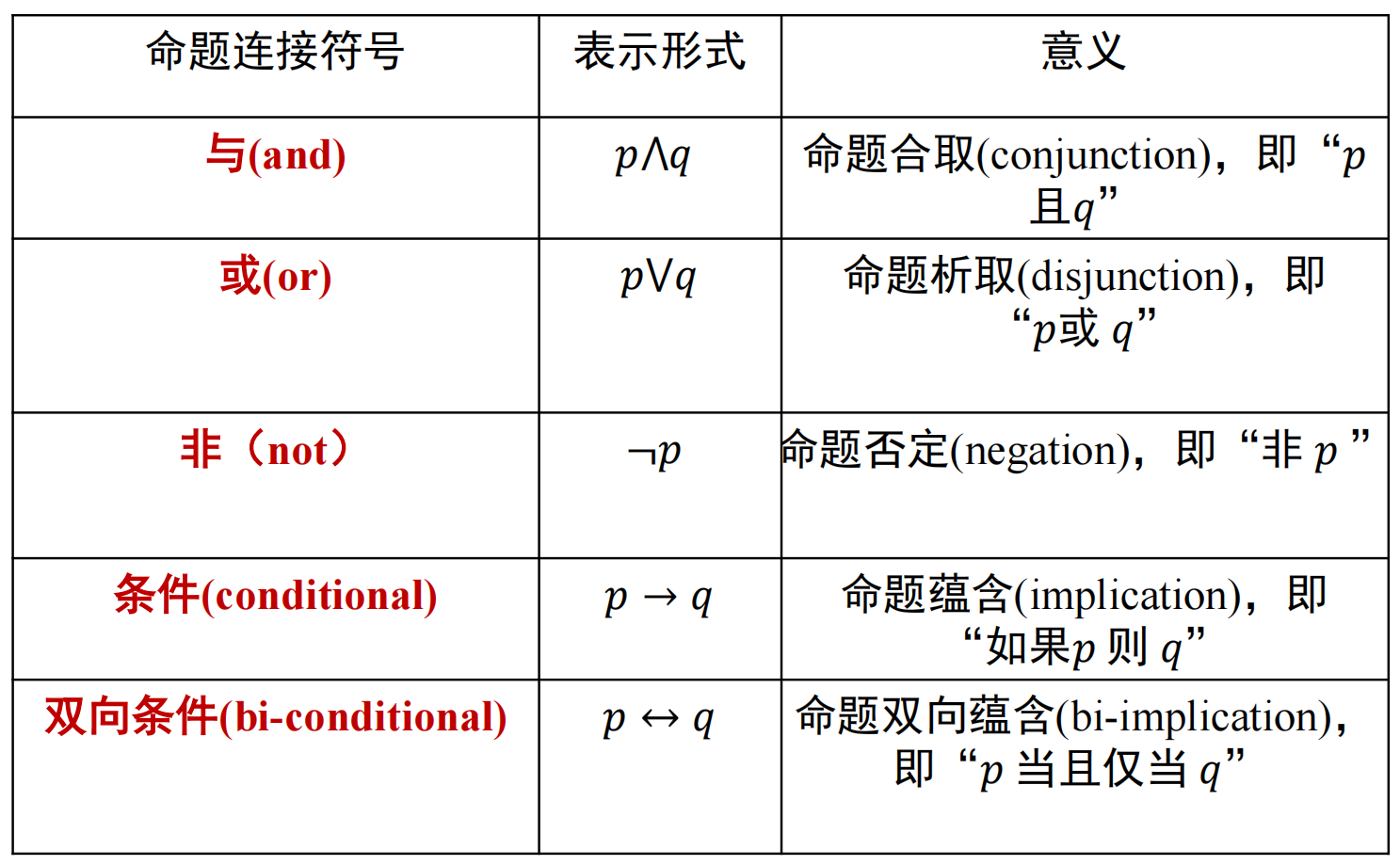
# 命题逻辑
![]()
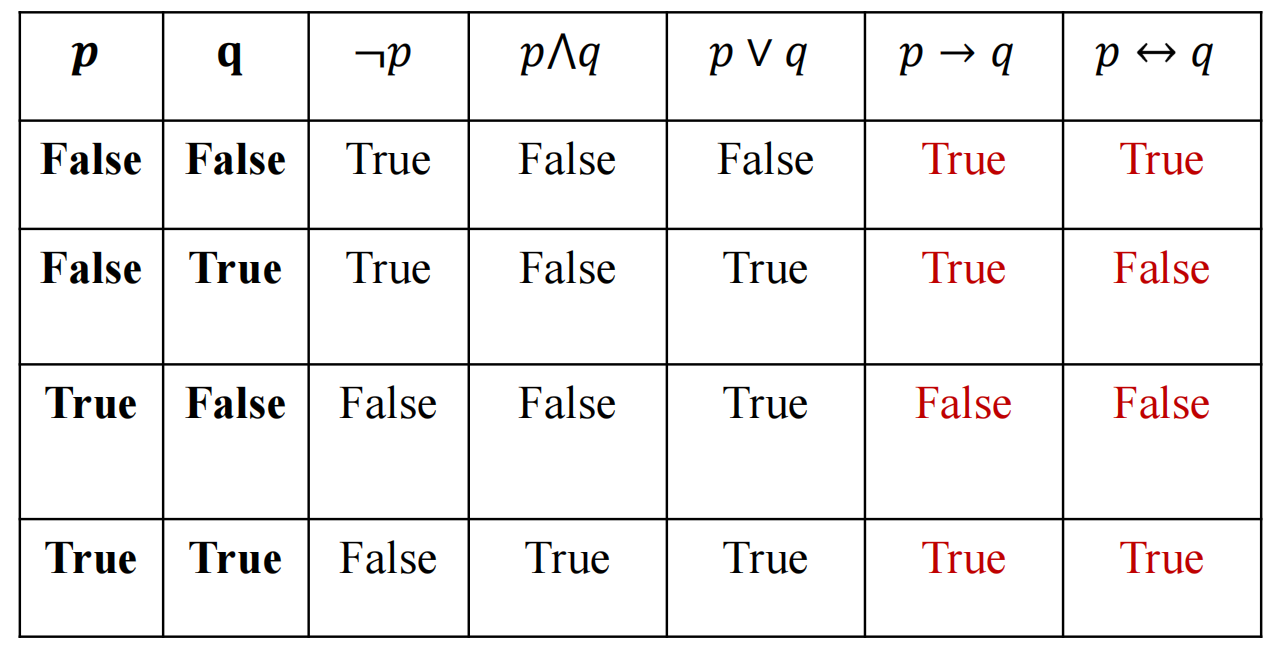
真值表:
![]()
“条件” 命题联结词中前提为假时命题结论永远为真,bi-conditional 只有两个都是 true 或者都是 false 才是 true
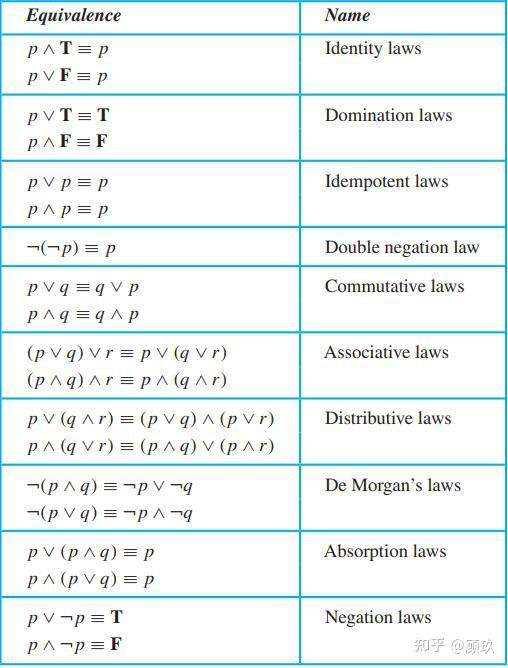
逻辑等价:给定命题 p 和命题 q,如果 p 和 q 在所有情况下都具有同样真假结果,那么 p 和 q 在逻辑上等价,一般用 ≡ 来表示,即 p ≡ q。
判断逻辑等价:画真值表
逻辑等价式:
![]()
![]()
- normal form
- 有限个简单合取式构成的析取式称为析取 (or) 范式
- 由有限个简单析取式构成的合取式称为合取 (and) 范式
# 谓词逻辑
在约束变元相同的情况下,量词的运算满足分配律:全称量词对析取没有分配律、存在量词对合取没有分配律
(∀x)(A(x)∨B(x))≡(∀x)A(x)∨(∀x)B(x)不成立
(∀x)(A(x)∧B(x))≡(∀x)A(x)∧(∀x)B(x)成立
(∃x)(A(x)∨B(x))≡(∃x)A(x)∨(∃x)B(x)成立
(∃x)(A(x)∧B(x))≡(∃x)A(x)∧(∃x)B(x)不成立
当公式中存在多个量词时,若多个量词都是全称量词或者都是存在量词,则量词的位置可以互换;若多个量词中既有全称量词又有存在量词,则量词的位置不可以随意互换
(∀x)(∀y)A(x,y)≡(∀y)(∀x)A(x,y)
(∃x)(∃y)A(x,y)≡(∃y)(∃x)A(x,y)
(∀x)(∀y)A(x,y)≡(∃y)(∀x)A(x,y)
(∀x)(∀y)A(x,y)≡(∃x)(∀y)A(x,y)
(∃y)(∀x)A(x,y)≡(∀x)(∃y)A(x,y)
(∃x)(∀y)A(x,y)≡(∀y)(∃x)A(x,y)
(∀x)(∃y)A(x,y)≡(∃y)(∃x)A(x,y)
(∀y)(∃x)A(x,y)≡(∃x)(∃y)A(x,y)
- 利用谓词逻辑进行推理
- 全称量词消去: (∀x)A(x)≡A(y)
- 全称量词引入: A(y)≡(∀x)A(x)
- 存在量词消去: (∃x)A(x)≡A(c)
- 存在量词引入: A(c)≡(∃x)A(x)
# 知识图谱推理
- 知识图谱可视为包含多种关系的图。在图中,每个节点是一个实体(如人名、地名、事件和活动等),任意两个节点之间的边表示这两个节点之间存在的关系。
- 可将知识图谱中任意两个相连节点及其连接边表示成一个三元组(triplet), 即 (left_node, relation, right_node)
两类代表性方法:
- 归纳逻辑程序设计 (inductive logic programming,ILP) 算法
- 路径排序算法(path ranking algorithm, PRA)
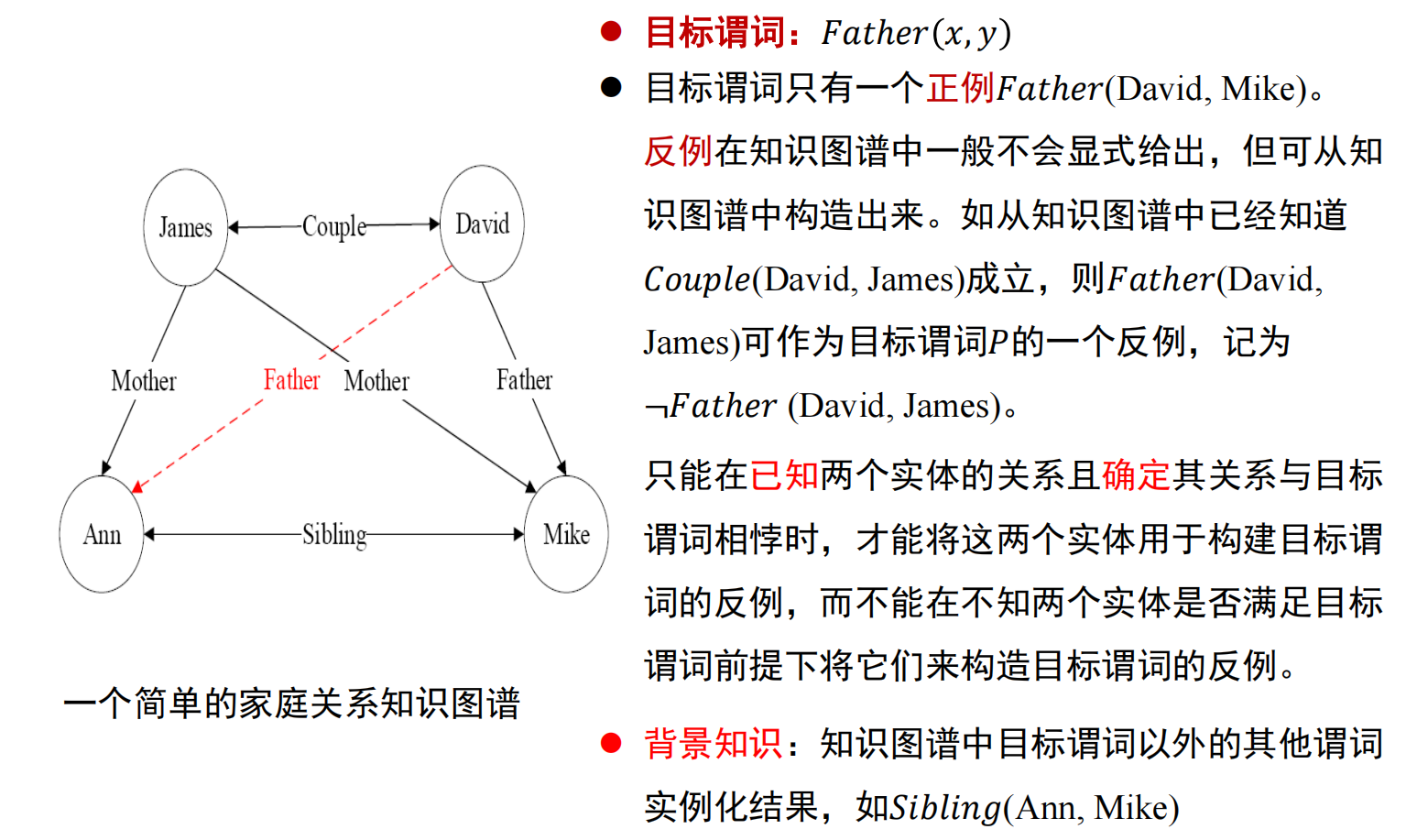
ILP: 一阶归纳学习 FOIL(First Order Inductive Learner)
推理手段:正例集合 + 反例集合 + 背景知识样例 ⟹ 目标谓词作为结论的推理规则
![]()
懒得写了,看 ppt 吧
![]()
推理规则覆盖所有正例且不覆盖任何反例的时候算法结束
PRA: 路径排序算法
![]()
(4) 的意思是看两个实体能不能通过 (3) 的关系从第一个走到第二个。
后面的 1 表示正例,-1 表示负例。
# 概率图推理
贝叶斯网络
![]()
要会算
马尔科夫逻辑网络
# 因果推理
因果定义:变量 X 是变量 Y 的原因,当且仅当保持其它所有变量不变的情况下,改变 X 的值能导致 Y 的值发生变化。
因果效应:因变量 X 改变一个单位时,果变量 Y 的变化程度
因果图是有向无环图
结构因果模型:结构因果模型由两组变量集合 U 和 V 以及一组函数 f 组成。其中,f 是根据模型中其他变量取值而给 V 中每一个变量赋值的函数
结构因果模型中的原因:如果变量 X 出现在给变量 X 赋值的函数中,如Y=f(X)+ϵ,则 X 是 Y 的直接原因
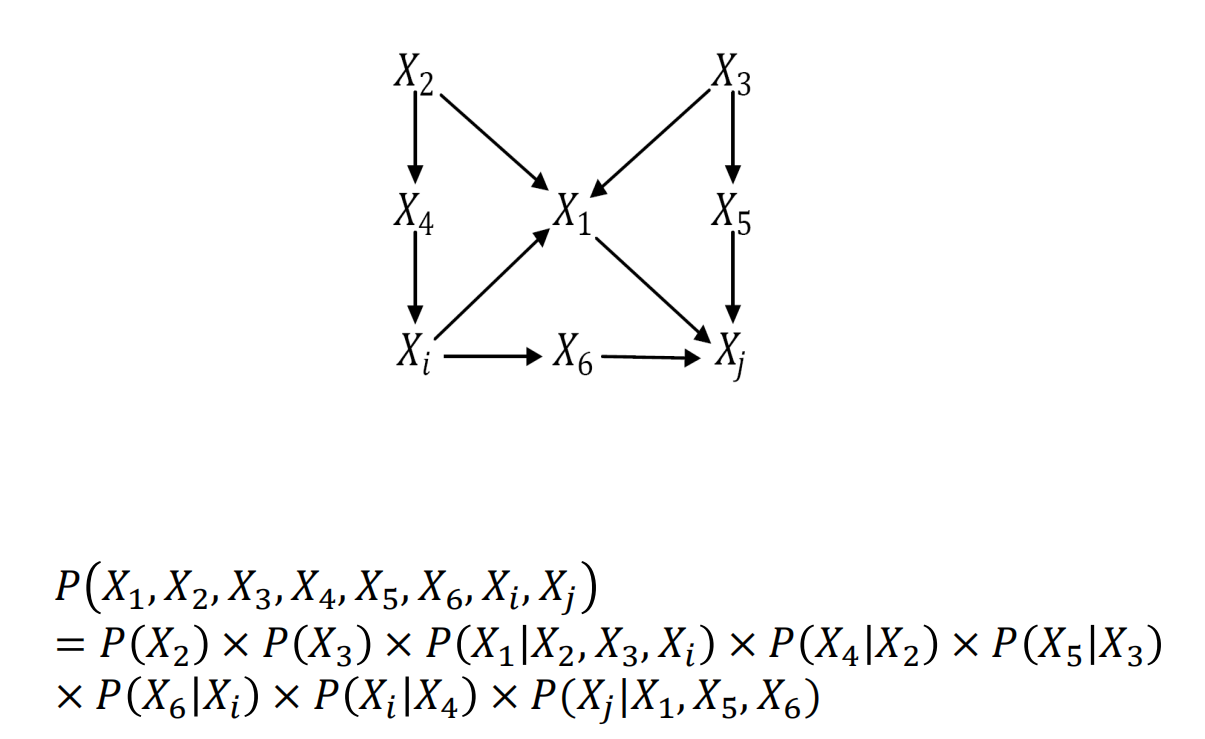
因果图中的联合概率分布:直接看图
![]()
因果图的基本结构:
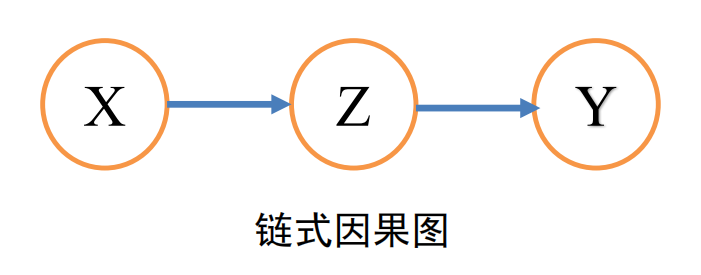
- 链结构
- ![]()
- 对于变量 X 和 Y,若 X 和 Y 之间只有一条单向的路径,变量 Z 是截断 (intercept) 该路径的集合中的任一变量,则在给定 Z 时,X 和 Y 条件独立。
P(X,Y∣Z)=P(X∣Z)P(Y∣Z)
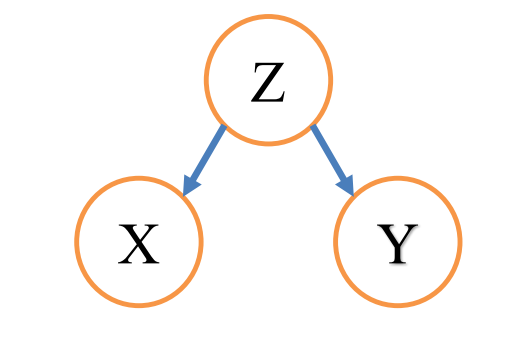
- 分连结构
- ![]()
P(X,Y∣Z)=P(Z)P(X,Y,Z)=P(Z)P(X∣Z)P(Y∣Z)P(Z)=P(X∣Z)P(Y∣Z)
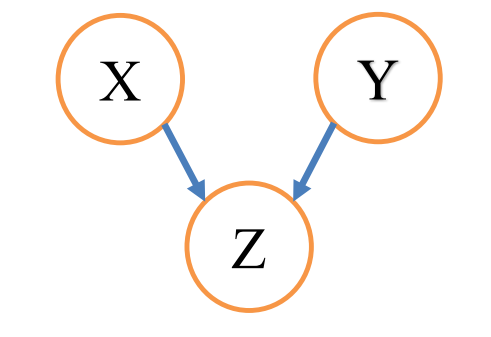
- 汇联结构
- ![]()
P(X,Y∣Z)=P(Z)P(X,Y,Z)=P(Z)P(X,Y,Z)=P(Z)P(X)P(Y)P(Z/X,Y)=P(X∣Z)P(Y∣Z)
# D - 分离 (directional separation, d-separation),可用于判断任意两个节点的相关性和独立性
- 限定集:已知或观察到的变量集合(给定的变量集合)
- 路径 p 被限定集 Z 阻塞 (block) 当且仅当:
- (1) 路径 p 含有链结构 A → B → C 或分连结构 A ← B → C 且中间节点 B 在 Z 中,或
- (2) 路径 p 含有汇连结构 A → B ← C 且汇连节点 B 及其后代都不在 Z 中。
- 若 Z 阻塞了节点 X 和节点 Y 之间的每一条路径,则称给定 Z 时,X 和 Y 是 D - 分离,即给定 Z 时,X 和 Y 条件独立
- 链式、分连中间节点在,汇联中间节点和后代不在则 D - 分离
因果定义:变量 X 是变量 Y 的原因,当且仅当保持其它所有变量不变的情况下,改变 X 的值能导致 Y 的值发生变化。
因果效应:因变量 X 改变一个单位时,果变量 Y 的变化程度因果推理的两个关键因素:
- 改变因变量 T
- 保证其它变量不变
干预:干预 (intervention) 指的是固定 (fix) 系统中的变量,然后改变系统,观察其他变量的变化。
为了与 X 自然取值 x 时进行区分,在对 X 进行干预时,引入 “do 算子”(do-calculus),记作 do (X = x)。
因此,P (Y = y|X = x) 表示的是当发现 X = x 时,Y= y 的概率;而 P (Y = y|do (X =x)) 表示的是对 X 进行干预,固定其值为 x 时,Y = y 的概率。
用统计学的术语来说,P (Y = y|X = x) 反映的是在取值为 x 的个体 X 上,Y 的总体分布;而 P (Y = y|do (X =x)) 反映的是如果将每一个 X 取值都固定为 x 时,Y 的总体分布。
因果效应差 / 平均因果效应 (ACE) 懒得写了看图吧
![]()
![]()
计算因果效应的关键在于计算操纵概率 (manipulatedprobability) Pm
调整公式:
P(Y=y∣do(X=x))=z∑P(Y=y∣X=x,Z=z)⋅P(Z=z)
对于 Z 的每一个取值 z,计算 X 和 Y 的条件概率并取均值
example
假设我们研究以下变量:
- X:是否服药
- X=1:服药
- X=0:不服药
- Y:是否康复
- Y=1:康复
- Y=0:未康复
- Z:性别
- Z=0:男
- Z=1:女
我们知道性别会影响:
- 是否选择服药(比如男性更倾向于尝试新药)
- 康复率(比如女性可能有更强的免疫力)
因此,性别 Z 是一个混杂变量,需要在分析中进行控制。
已知:
| Z(性别) |
P(Z) |
P(Y=1 | X=1, Z) |
P(Y=1 | X=0, Z) |
| 男(0) |
0.6 |
0.7 |
0.4 |
| 女(1) |
0.4 |
0.5 |
0.3 |
我们想知道:
如果强制所有人都服药(即 do(X=1)),整体康复率是多少?
也就是要计算:
P(Y=1∣do(X=1))
根据调整公式:
P(Y=1∣do(X=1))=z∑P(Y=1∣X=1,Z=z)⋅P(Z=z)
代入数据计算
P(Y=1∣do(X=1))=P(Y=1∣X=1,Z=0)⋅P(Z=0)+P(Y=1∣X=1,Z=1)⋅P(Z=1)
=0.7×0.6+0.5×0.4=0.42+0.2=0.62
(因果效应) 给定因果图 G,PA 表示 X 的父节点集合,则 X 对 Y 的因果效应为
P(Y=y∣do(X=x))=z∑P(Y=y∣X=x,PA=z)⋅P(PA=z)
后门调整:
不写了