
# K-Means
问题描述:如何将 n 个数据依据其相似度大小将它们分别聚类到 k 个集合,使得每个数据仅属于一个聚类集合。
- 初始化质心:随机选择 k 个数据点作为初始质心。
- 分配数据点:对于每个数据点,计算它与所有质心的距离,并将其分配到距离最近的质心所在的簇中
- 更新质心:对于每个簇,计算该簇内所有数据点的平均值,将该平均值作为新的质心。
- 迭代过程:重复执行分配和更新步骤,直到质心不再发生变化或达到预设的最大迭代次数。
# 主成分分析 (PCA)
- 输入:n 个 d 维样本数据所构成的矩阵,降维后的维数 l
- 输出:映射矩阵
算法步骤:
- 对于每个样本数据 进行中心化处理:
- 计算原始样本数据的协方差矩阵:
-
对协方差矩阵 进行特征值分解,对所得特征根按其值大到小排序
-
取前 个最大特征根所对应特征向量 组成映射矩阵\mathbf
-
将每个样本数据 按照如下方法降维:
区分:
| 维度 | PCA | LDA |
|---|---|---|
| 类型 | 无监督 | 有监督 |
| 目标 | 最大化方差,保留主要分布信息 | 最大化类间距离,最小化类内距离 |
| 是否使用类别信息 | ? 不使用 | ? 使用 |
| 适用任务 | 数据压缩、可视化、去噪 | 分类任务的特征提取 |
| 降维后维度上限 | 可任意,但一般小于原维度 | 最多降到 维( 是类别数) |
| 数学基础 | 协方差矩阵的特征值分解 | 类间 / 类内散度矩阵的广义特征值分解 |
- 其他降维方法:
- 非负矩阵分解 (non-negative matrix factorization, NMF)
- 多维尺度法(Metric multidimensional scaling, MDS)
- 局部线性嵌入(Locally Linear Embedding,LLE)
# 特征人脸方法
输入时将每幅人脸图像转换成列向量
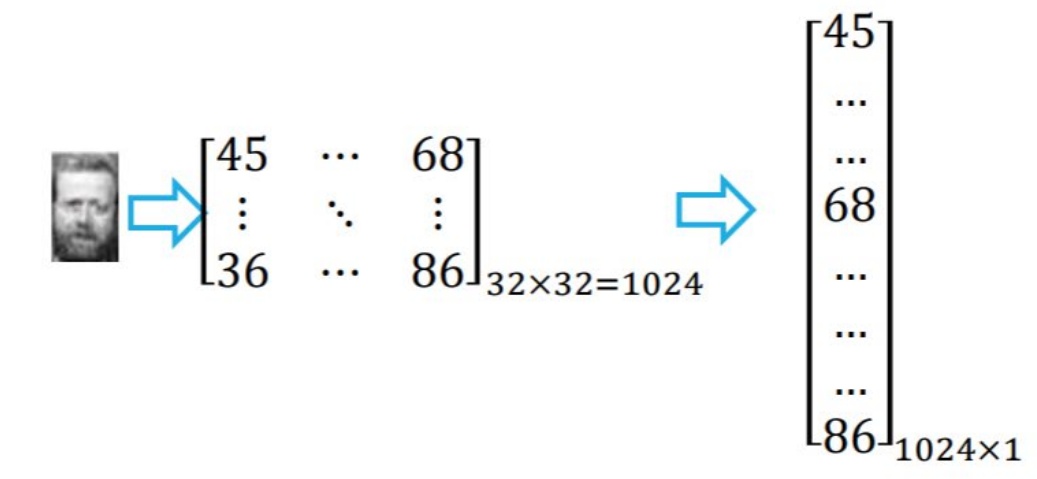
算法描述
- 输入: 个 1024 维人脸样本数据所构成的矩阵,降维后的维数
- 输出:映射矩阵(其中每个 是一个特征人脸)
算法步骤
-
中心化处理:
- 对每个人脸样本数据 进行中心化处理:
- 对每个人脸样本数据 进行中心化处理:
-
计算协方差矩阵:
- 计算原始人脸样本数据的协方差矩阵:
- 计算原始人脸样本数据的协方差矩阵:
-
特征值分解:
- 对协方差矩阵 进行特征值分解,对所得特征根按从大到小排序:
- 对协方差矩阵 进行特征值分解,对所得特征根按从大到小排序:
-
构建映射矩阵:
- 取前 个最大特征根所对应特征向量 组成映射矩阵。
-
数据降维:
- 将每个人脸图像 按照如下方法降维:
- 将每个人脸图像 按照如下方法降维:
(其实用的是 pca,多的一步就是输入的时候把 32*32 的图摊开成 1024*1 的列向量而已)
# 潜在语义分析(Latent Semantic Analysis, LSA)
步骤
-
构建单词 - 文档矩阵:
- 构建一个单词 - 文档矩阵,其中每个元素 表示第 个单词在第 个文档中的频率(通常使用词频 - 逆文档频率 TF-IDF 进行加权)。
-
奇异值分解(SVD):
- 对单词 - 文档矩阵 进行奇异值分解,即,其中 和 分别是左奇异向量和右奇异向量组成的矩阵, 是对角矩阵,其对角线上的元素是 的奇异值(按降序排列)。
-
选择前 个最大奇异值及对应的奇异向量:
- 选取前 个最大的奇异值及其对应的奇异向量,形成低秩逼近矩阵。这里 的选择取决于保留多少原始信息量,通常根据累积能量准则或经验确定。
-
重建矩阵并挖掘语义关系:
- 使用 代替原始矩阵,可以计算任意两个文档之间的相似度(如皮尔逊相关系数),从而发现文档 - 文档之间的关联关系。
- 同样地,也可以用于探索单词 - 单词、单词 - 文档间的隐含关系。
# 期望最大化算法(Expectation-Maximization Algorithm, EM)
EM 算法是一种迭代方法,主要用于含有隐变量的概率模型参数估计问题。它分为 E 步(求期望)和 M 步(最大化),通过迭代方式逼近模型参数的最大似然估计值。
步骤
-
初始化模型参数:
- 首先为模型参数设定初始值(例如高斯混合模型中的均值、方差等)。
-
E 步(Expectation Step):计算隐变量
- 基于当前的模型参数,计算隐变量的后验概率分布。对于每一个样本 和可能的隐变量,计算,其中 表示当前的模型参数。
-
M 步(Maximization Step):最大化似然函数和更新模型参数
- 根据观测数据、隐变量 的后验概率分布,重新估计模型参数,以最大化完整数据的对数似然函数 的期望。
-
重复 E 步和 M 步:
- 不断重复执行 E 步和 M 步,直到模型参数收敛或者达到预定的迭代次数为止。
具体的没看懂,等我懂了再说
