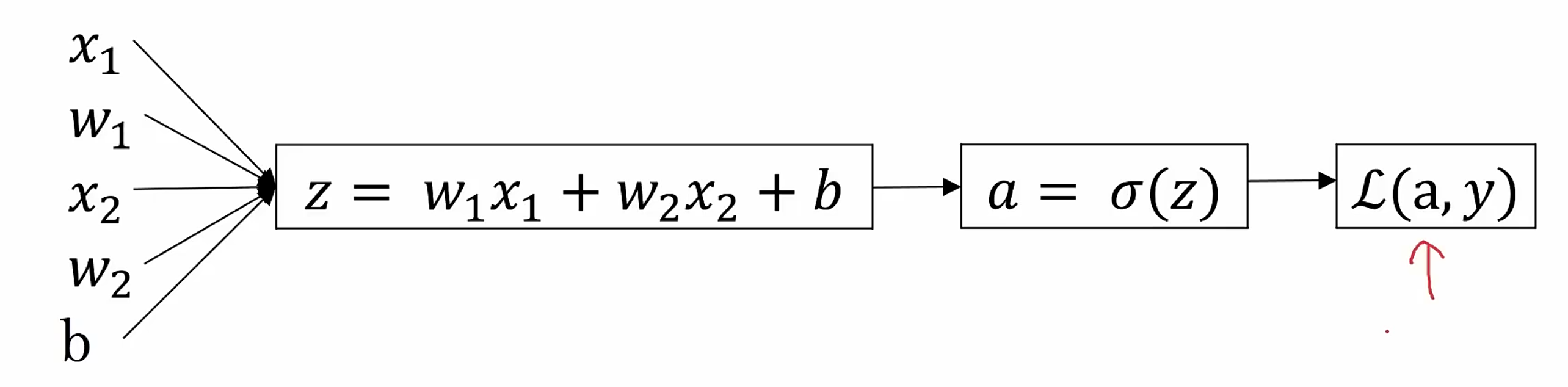吴恩达
# Neural Network
Example: House Price Prediction
Standard Neural Network, CNN (convolutional, 图像等), RNN (recurrent, 时序序列)
Structured Data: 表格数据
为什么效果好?
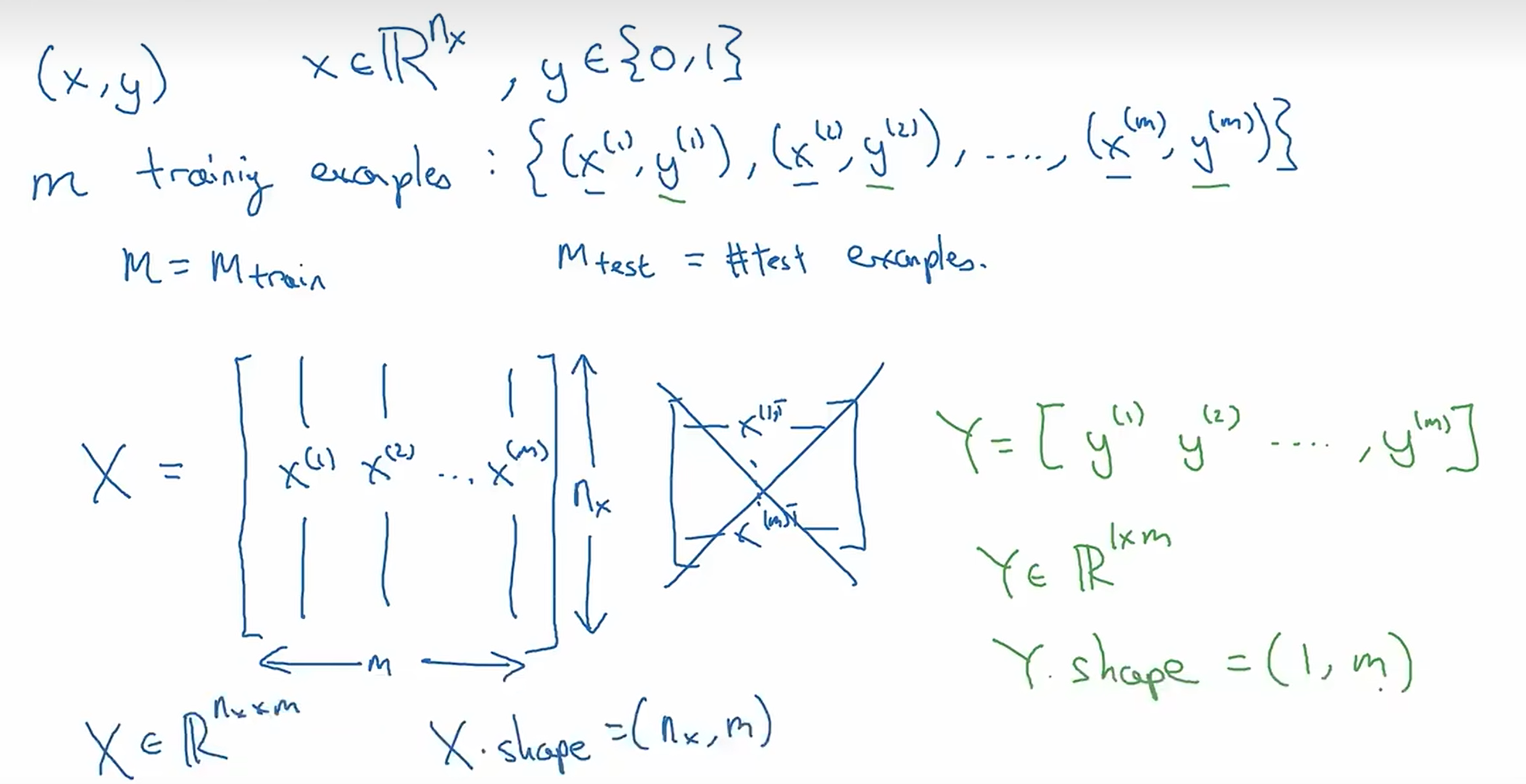
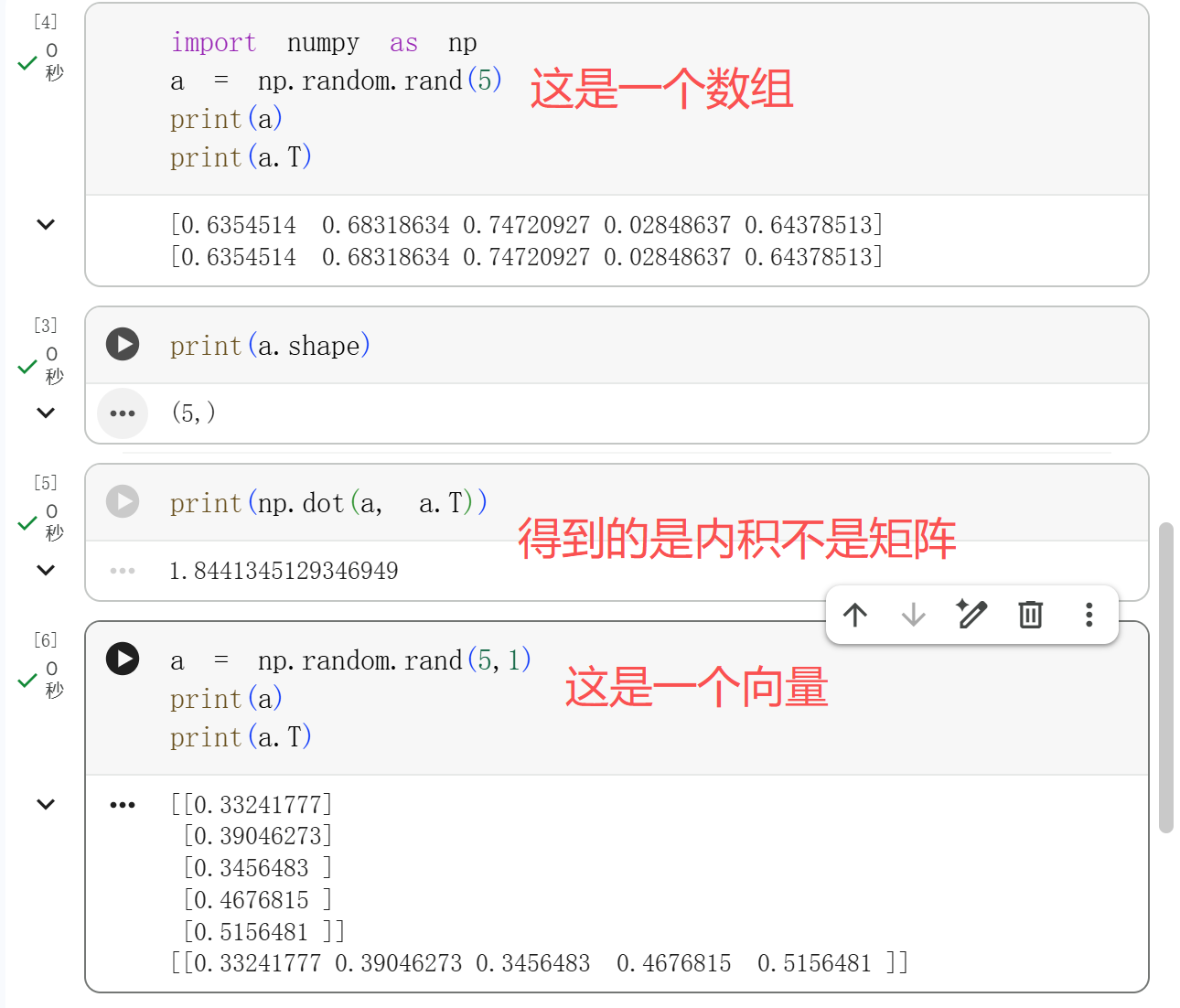
# Basic of NN# Binary Classification输入 x 输出 0 或 1n x × m n_x \times m n x × m 1 × m 1 \times m 1 × m
# Logistic Regression一种二分类算法y ^ = P ( y = 1 ∣ x ) , x ∈ R n \hat{y} = P(y=1|x), x \in \mathbb{R}^n y ^ = P ( y = 1 ∣ x ) , x ∈ R n y ^ = σ ( w T x + b ) \hat{y} = \sigma(w^Tx + b) y ^ = σ ( w T x + b )
w w w n x × 1 n_x \times 1 n x × 1 σ ( z ) = 1 1 + e − z \sigma(z) = \frac{1}{1+e^{-z}} σ ( z ) = 1 + e − z 1 y ^ ∈ [ 0 , 1 ] \hat{y} \in [0, 1] y ^ ∈ [ 0 , 1 ]
math版 1 2 def basic_sigmoid (x ): return 1 /(1 + math.exp(-x))
numpy版 1 2 def basic_sigmoid (x ): return 1 /(1 + np.exp(-x))
梯度函数 1 2 3 4 def sigmoid_derivative (x ): s = sigmoid(x) ds = s(1 - s) return ds
# Logistic Regression Cost FunctionGiven( x ( 1 ) , y ( 1 ) ) , . . . , ( x ( m ) , y ( m ) ) {(x^(1), y^(1)), ..., (x^(m), y^(m))} ( x ( 1 ) , y ( 1 ) ) , . . . , ( x ( m ) , y ( m ) ) y ^ ( i ) ≈ y ( i ) \hat{y}^{(i)} \approx y^{(i)} y ^ ( i ) ≈ y ( i ) Loss function: 对于一个样本来说L ( y ^ , y ) = − [ y log ( y ^ ) + ( 1 − y ) log ( 1 − y ^ ) ] L(\hat{y}, y) = -[y \log(\hat{y}) + (1-y) \log(1-\hat{y})] L ( y ^ , y ) = − [ y log ( y ^ ) + ( 1 − y ) log ( 1 − y ^ ) ] Cost function: 对于m m m
J ( w , b ) = 1 m ∑ i = 1 m L ( y ^ ( i ) , y ( i ) ) = − 1 m ∑ i = 1 m [ y ( i ) log ( y ^ ( i ) ) + ( 1 − y ( i ) ) log ( 1 − y ^ ( i ) ) ] J(w, b) = \frac{1}{m} \sum_{i=1}^m L(\hat{y}^{(i)}, y^{(i)})
= -\frac{1}{m} \sum_{i=1}^m [y^{(i)} \log(\hat{y}^{(i)}) + (1-y^{(i)}) \log(1-\hat{y}^{(i)})]
J ( w , b ) = m 1 i = 1 ∑ m L ( y ^ ( i ) , y ( i ) ) = − m 1 i = 1 ∑ m [ y ( i ) log ( y ^ ( i ) ) + ( 1 − y ( i ) ) log ( 1 − y ^ ( i ) ) ]
找到一组参数w , b w,b w , b J ( w , b ) J(w,b) J ( w , b )
# Gradient Descent梯度下降J ( w ) J(w) J ( w )
r e p e a t { w : = w − α ∂ J ( w ) ∂ w } repeat \{
w := w - \alpha \frac{\partial J(w)}{\partial w}
\}
r e p e a t { w : = w − α ∂ w ∂ J ( w ) }
α \alpha α
对于J ( w , b ) J(w, b) J ( w , b )
r e p e a t { w : = w − α ∂ J ( w , b ) ∂ w b : = b − α ∂ J ( w , b ) ∂ b } repeat \{
w := w - \alpha \frac{\partial J(w, b)}{\partial w}
b := b - \alpha \frac{\partial J(w, b)}{\partial b}
\}
r e p e a t { w : = w − α ∂ w ∂ J ( w , b ) b : = b − α ∂ b ∂ J ( w , b ) }
Derivative 表示函数的变化率,Gradient 表示多变量函数的变化率方向和大小
# Logistic Regression Gradient Descent在一个样本上:L ( a , y ) L(a, y) L ( a , y ) a a a
∂ L ∂ a = − y a + 1 − y 1 − a \frac{\partial L}{\partial a} = -\frac{y}{a} + \frac{1-y}{1-a}
∂ a ∂ L = − a y + 1 − a 1 − y
再用a a a z z z
∂ L ∂ z = ∂ L ∂ a ⋅ ∂ a ∂ z = − y a + 1 − y 1 − a ⋅ a ( 1 − a ) = a − y \frac{\partial L}{\partial z} = \frac{\partial L}{\partial a} \cdot \frac{\partial a}{\partial z}
= -\frac{y}{a} + \frac{1-y}{1-a} \cdot a(1-a)
= a - y
∂ z ∂ L = ∂ a ∂ L ⋅ ∂ z ∂ a = − a y + 1 − a 1 − y ⋅ a ( 1 − a ) = a − y
再用z z z w w w
z = w T x + b = w 1 x 1 + w 2 x 2 + . . . + w n x n + b 所以 ∂ z ∂ w i = x i z = w^Tx + b = w_1 x_1 + w_2 x_2 + ... + w_n x_n + b
所以\frac{\partial z}{\partial w_i} = x_i
z = w T x + b = w 1 x 1 + w 2 x 2 + . . . + w n x n + b 所 以 ∂ w i ∂ z = x i
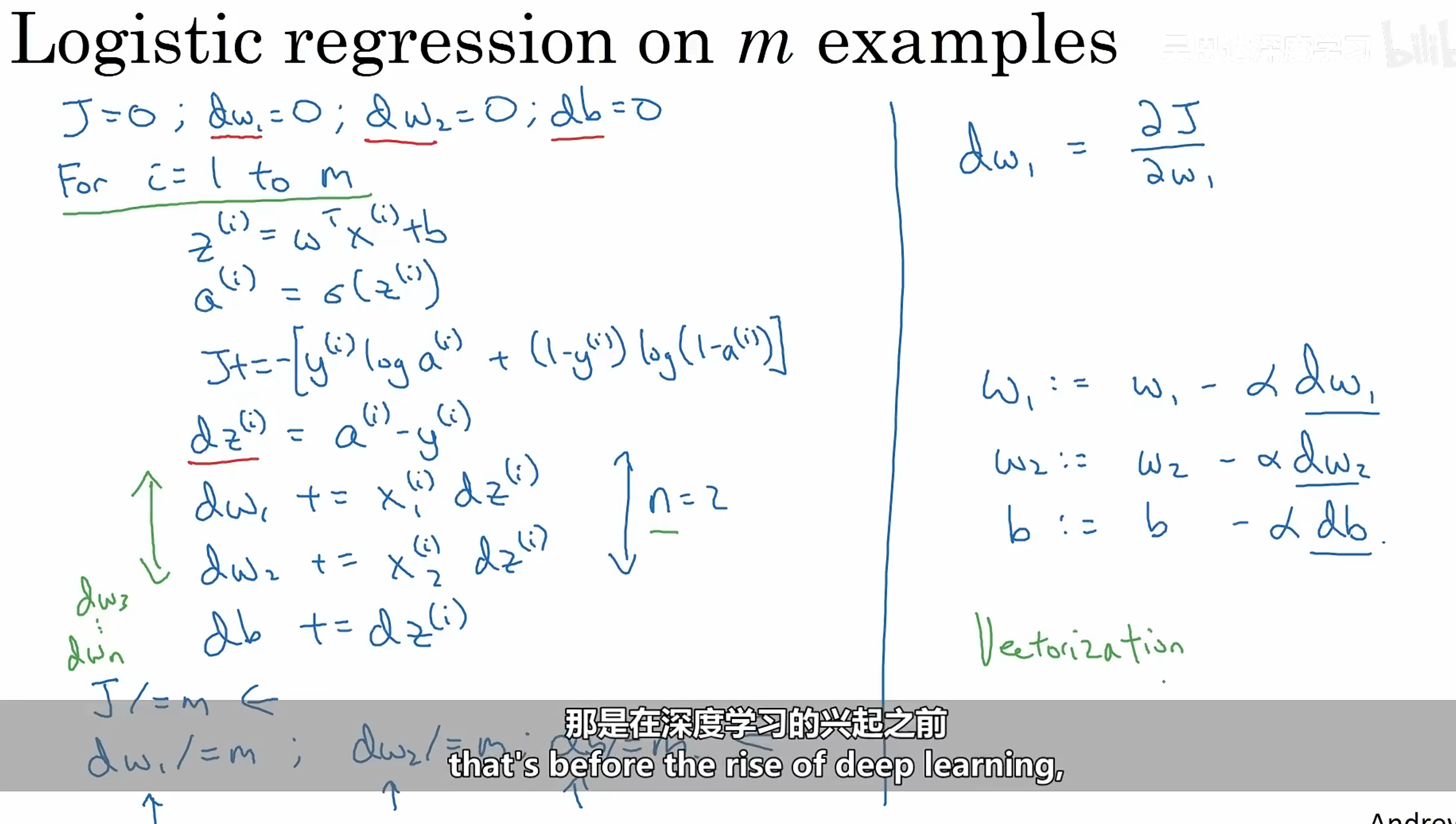
# Logistic Regression Gradient Descent on m samples对于 m 个样本:
J ( w , b ) = 1 m ∑ i = 1 m L ( a ( i ) , y ( i ) ) w h e r e a ( i ) = σ ( z ( i ) ) = σ ( w T x ( i ) + b ) J(w, b) = \frac{1}{m} \sum_{i=1}^m L(a^{(i)}, y^{(i)})
where a^{(i)} = \sigma(z^{(i)}) = \sigma(w^Tx^{(i)} + b)
J ( w , b ) = m 1 i = 1 ∑ m L ( a ( i ) , y ( i ) ) w h e r e a ( i ) = σ ( z ( i ) ) = σ ( w T x ( i ) + b )
串行的话只能用 for 循环,但是太慢了,所以可以利用矩阵运算
# Vectorization向量化
u = A v u i = ∑ j = 1 n A i j v j u = Av
u_i = \sum_{j=1}^n A_{ij} v_j
u = A v u i = j = 1 ∑ n A i j v j
代码实现 给定一个列向量 v
v T = [ v 1 , v 2 , . . . , v n ] v^T = [v_1, v_2, ..., v_n]
v T = [ v 1 , v 2 , . . . , v n ]
对 v 中每个元素做指数运算
u T = [ e v 1 , e v 2 , . . . , e v n ] u^T = [e^{v_1}, e^{v_2}, ..., e^{v_n}]
u T = [ e v 1 , e v 2 , . . . , e v n ]
for循环 1 2 3 u = np.zeros((n,1 )) for i in range (n): u[i] = np.exp(v[i])
改进为:
改进后的逻辑回归 # Vectorization for Logistic Regression对于逻辑回归,尝试移除一个 for 循环
Logistic Regression 1 2 Z = np.dot(w.T, X) + b A = 1 / (1 + np.exp(-Z))
# Vectorized Logistic Regression’s Gradient Computation
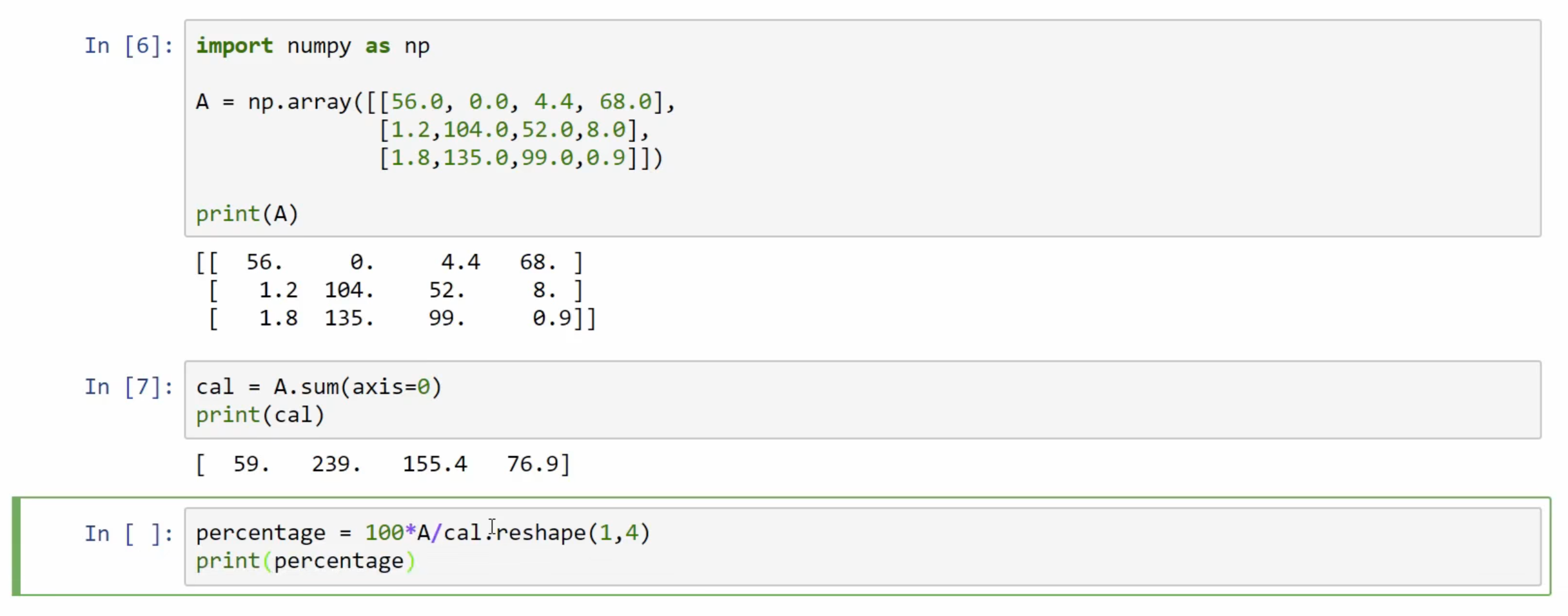
# Broadcasting in python广播机制axis 参数指定广播的方向:axis = 0 : 垂直方向axis = 1 : 水平方向
python/numpy:
归一化 1 2 x_norm = np.linalg.norm(x, axis=1 , keepdims=True ) x = x / x_norm
# 用 numpy 实现 softmax用于多分类
for x ∈ R 1 × n , s o f t m a x ( x ) = s o f t m a x ( [ x 1 x 2 . . . x n ] ) = [ e x 1 ∑ j e x j e x 2 ∑ j e x j . . . e x n ∑ j e x j ] \text{for } x \in \mathbb{R}^{1\times n} \text{, } softmax(x) = softmax(\begin{bmatrix} x_1 && x_2 && ... && x_n \end{bmatrix}) = \begin{bmatrix} \frac{e^{x_1}}{\sum_{j}e^{x_j}} && \frac{e^{x_2}}{\sum_{j}e^{x_j}} && ... && \frac{e^{x_n}}{\sum_{j}e^{x_j}} \end{bmatrix}
for x ∈ R 1 × n , s o f t m a x ( x ) = s o f t m a x ( [ x 1 x 2 . . . x n ] ) = [ ∑ j e x j e x 1 ∑ j e x j e x 2 . . . ∑ j e x j e x n ]
For a matrix x ∈ R m × n , let x i j denote the element in the i -th row and j -th column. \text{For a matrix } x \in \mathbb{R}^{m \times n}, \text{ let } x_{ij} \text{ denote the element in the } i\text{-th row and } j\text{-th column.}
For a matrix x ∈ R m × n , let x i j denote the element in the i -th row and j -th column.
s o f t m a x ( x ) = s o f t m a x [ x 11 x 12 x 13 … x 1 n x 21 x 22 x 23 … x 2 n ⋮ ⋮ ⋮ ⋱ ⋮ x m 1 x m 2 x m 3 … x m n ] = [ e x 11 ∑ j e x 1 j e x 12 ∑ j e x 1 j e x 13 ∑ j e x 1 j … e x 1 n ∑ j e x 1 j e x 21 ∑ j e x 2 j e x 22 ∑ j e x 2 j e x 23 ∑ j e x 2 j … e x 2 n ∑ j e x 2 j ⋮ ⋮ ⋮ ⋱ ⋮ e x m 1 ∑ j e x m j e x m 2 ∑ j e x m j e x m 3 ∑ j e x m j … e x m n ∑ j e x m j ] = ( s o f t m a x (first row of x) s o f t m a x (second row of x) . . . s o f t m a x (last row of x) ) softmax(x) = softmax\begin{bmatrix} x_{11} & x_{12} & x_{13} & \dots & x_{1n} \\ x_{21} & x_{22} & x_{23} & \dots & x_{2n} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ x_{m1} & x_{m2} & x_{m3} & \dots & x_{mn} \end{bmatrix} = \begin{bmatrix} \frac{e^{x_{11}}}{\sum_{j}e^{x_{1j}}} & \frac{e^{x_{12}}}{\sum_{j}e^{x_{1j}}} & \frac{e^{x_{13}}}{\sum_{j}e^{x_{1j}}} & \dots & \frac{e^{x_{1n}}}{\sum_{j}e^{x_{1j}}} \\ \frac{e^{x_{21}}}{\sum_{j}e^{x_{2j}}} & \frac{e^{x_{22}}}{\sum_{j}e^{x_{2j}}} & \frac{e^{x_{23}}}{\sum_{j}e^{x_{2j}}} & \dots & \frac{e^{x_{2n}}}{\sum_{j}e^{x_{2j}}} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ \frac{e^{x_{m1}}}{\sum_{j}e^{x_{mj}}} & \frac{e^{x_{m2}}}{\sum_{j}e^{x_{mj}}} & \frac{e^{x_{m3}}}{\sum_{j}e^{x_{mj}}} & \dots & \frac{e^{x_{mn}}}{\sum_{j}e^{x_{mj}}} \end{bmatrix} = \begin{pmatrix} softmax\text{(first row of x)} \\ softmax\text{(second row of x)} \\ ... \\ softmax\text{(last row of x)} \\ \end{pmatrix}
s o f t m a x ( x ) = s o f t m a x ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ x 1 1 x 2 1 ⋮ x m 1 x 1 2 x 2 2 ⋮ x m 2 x 1 3 x 2 3 ⋮ x m 3 … … ⋱ … x 1 n x 2 n ⋮ x m n ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ ∑ j e x 1 j e x 1 1 ∑ j e x 2 j e x 2 1 ⋮ ∑ j e x m j e x m 1 ∑ j e x 1 j e x 1 2 ∑ j e x 2 j e x 2 2 ⋮ ∑ j e x m j e x m 2 ∑ j e x 1 j e x 1 3 ∑ j e x 2 j e x 2 3 ⋮ ∑ j e x m j e x m 3 … … ⋱ … ∑ j e x 1 j e x 1 n ∑ j e x 2 j e x 2 n ⋮ ∑ j e x m j e x m n ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ = ⎝ ⎜ ⎜ ⎜ ⎛ s o f t m a x (first row of x) s o f t m a x (second row of x) . . . s o f t m a x (last row of x) ⎠ ⎟ ⎟ ⎟ ⎞
softmax 1 2 3 4 def softmax (x ): x_exp = np.exp(x) s = np.sum (x_exp, asix = 1 , keepdims = True ) return x_exp / s
# Logistic Regression’s Cost Functioni f y = 1 : p ( y ∣ x ) = y ^ i f y = 0 : p ( y ∣ x ) = 1 − y ^ if y = 1: p(y|x) = \hat{y}
if y = 0: p(y|x) = 1 - \hat{y}
i f y = 1 : p ( y ∣ x ) = y ^ i f y = 0 : p ( y ∣ x ) = 1 − y ^
解释:p (y|x) 是模型预测正确的概率,在已知输入 x 的情况下,真实标签 y 出现的概率
L ( y ^ , y ) = − [ y log ( y ^ ) + ( 1 − y ) log ( 1 − y ^ ) ] L(\hat{y}, y) = -[y \log(\hat{y}) + (1-y) \log(1-\hat{y})]
L ( y ^ , y ) = − [ y log ( y ^ ) + ( 1 − y ) log ( 1 − y ^ ) ]
就是损失函数
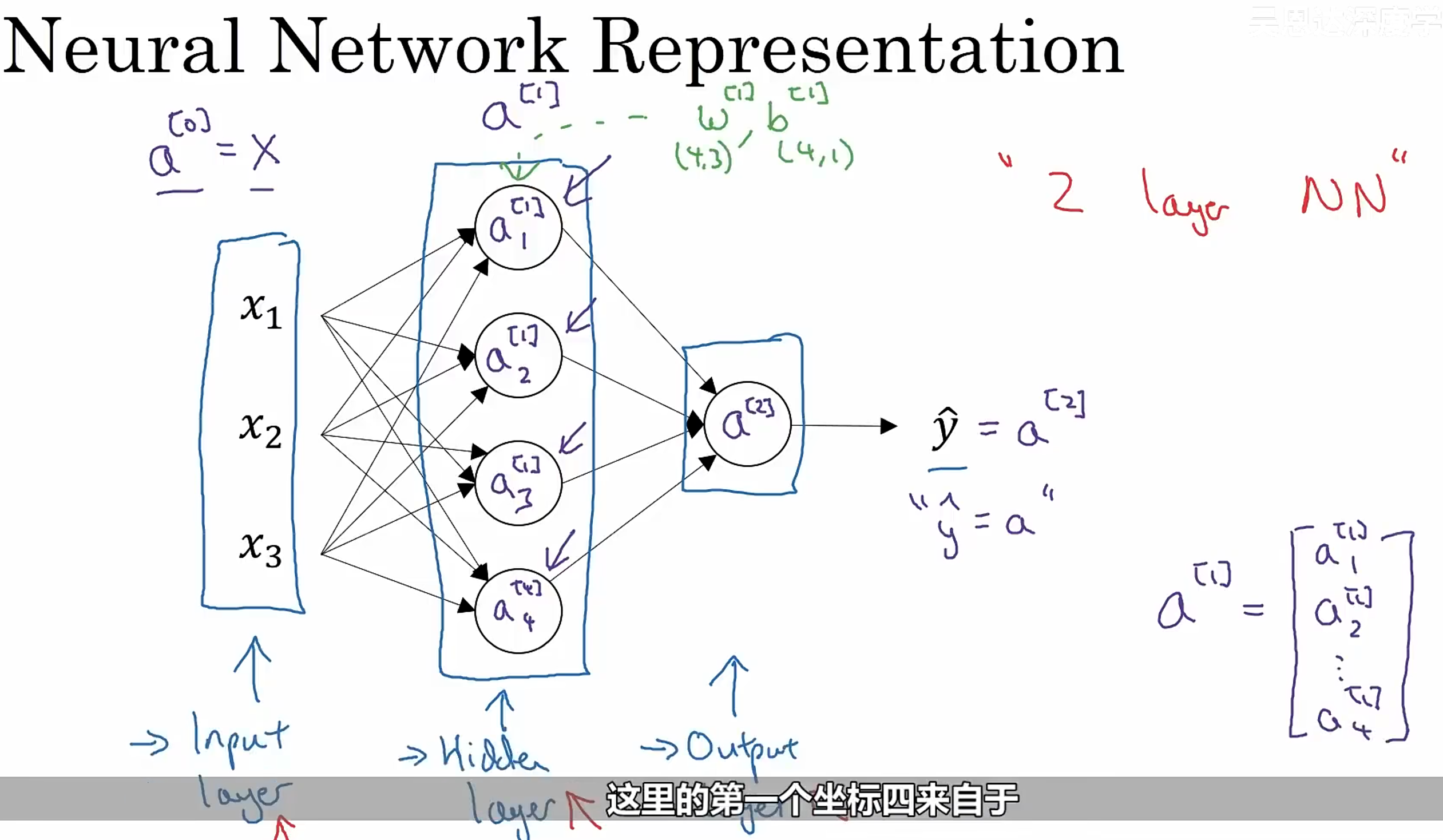
# Neural Network Overview# Neural Network Representation单隐藏层的 NN:a [ 0 ] a^{[0]} a [ 0 ] a [ 1 ] a^{[1]} a [ 1 ] a [ 2 ] a^{[2]} a [ 2 ]
# Computing a Neural Network’s Output一个带两层隐藏层的神经网络,最后用 Sigmoid 输出
# Vectorizing across multiple examples